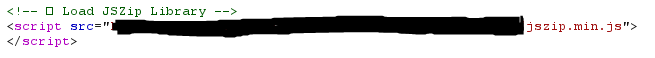This is how I Reverse-Engineered an Instagram phising scam
Cracking open a fake Instagram page designed to steal user credentials. This blog goes into how modern phishing pages operate and the steps you can take to stay safe online.


The Scenario :
A few weeks ago my friend sent me a link to an instagram profile which had a suspicious link in the bio. It had the text “Limited time Buy 1 get 1 free vouchers”. This text was a hyperlink to an external website. The instagram profile in this situation looked like it sold jewellery like rings, necklaces, bracelets and other various stuff. One thing that made this profile stand out was that it had a decent amount of posts on its page and each post had a believable amount of interactions on it (likely bot profiles). It also had a decent amount of followers and following which actually matched the number of post interactions. Most scam profiles don't go through this amount of effort which made this profile actually kind of believable apart from the link which made me a bit curious.
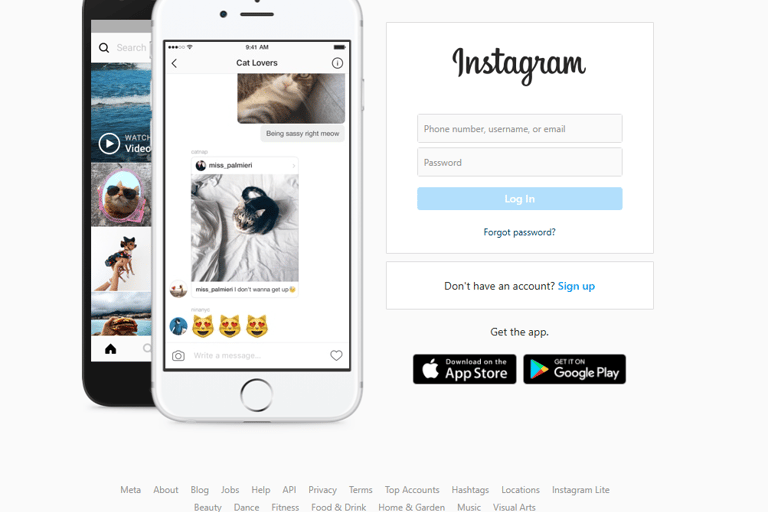
I then started up my virtual machine along with connecting to a VPN and visited the url on that profile. It redirected me a few times and then took me to a 1:1 replica of an instagram login page which seemed real until I saw the url which was not of a real instagram login page.This alone was enough to get me interested into finding out what this link really was.
The fake page ^
Digging deep:
My next step to analyze the link was to see what requests it was making while redirecting the victim and finding out where exactly it was redirecting the victim to. I opened up Burpsuite and started up a proxy browser and enabled the intercept traffic option. I then pasted the link and at first just forwarded all the requests through the proxy till the login which I saw on the first visit showed up. I then navigated to the HTTP proxy tab on burpsuite to analyze all the redirects. It was redirecting the victim a total of 4 times, the 4th time being the “real” login page which we will get to shortly. The first one was a cloudflare link which I assume was being used for their CDN (Content Delivery Network) to fetch the needed scripts and what not. The remaining three redirects were just subdomains of the main original link. At this stage going through the other redirect requests and their responses felt like the best next thing to do to uncover the workings of the login page.
The burpsuite redirect chain ^
The login page with a twist:
Going through all the redirects it was just throwing me to a new url except the last one which was the login page. Soo…. I found it right? Except this wasn’t a static login page it was using JSZip to fetch and display the login page by getting a zip file with the code, decompressing it and then injecting it into an iframe on the page. In simple terms the website was a blank page and imagine it has an empty container. The website runs a javascript library known as JSZip which fetches the code file for the login page from an external location and then places it into the empty container on the website to display the login page. This method of displaying the login page is a smart one as it can avoid being detected and flagged by scanners. The entire login page is assembled in the victim’s browser session.
Part of the code that initialises the JSZip library ^
Part of the code that fetches “file-2.zip” ^
Can we get hold of the code? :
Now seeing that the file is being injected in the browser instead of being a static webpage my next move was to somehow get hold of the file which contained the code. I went through the requests and responses I had captured and saw that the file was being fetched from a url and it was named file-2.zip. To fetch the file I ran curl and got the response “Server verification failed”. This just shows that there is some kind of verification happening in the backend to verify that a real victim’s browser is fetching the file. In this case the blank page had a small javascript code which had a cryptographic puzzle which is solved by the victims bowser to give a specific cookie which the backend server is expecting, only after receiving the cookies does it send the file with the code to the browser.This again is a very clever step taken by the website developer as basic web scanners by default do not run java script which leaves them no response and the file is not served to them.
This leaves me trying to figure out how to get my hands on that file. I tried a lot of different options but then I had an idea to add the solved cryptographic puzzle from my browser along with the cookie inside my curl request including other required headers. This successfully fetched me the file and downloaded it on my virtual machine.
Part of the cryptographic puzzle that the victims browser solves ^
What hides in the code:
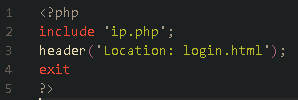
The file was in a compressed archive format (.Zip) which I extracted. What left me surprised was that the website contained security measures on how the content is served to the victim and to make sure that no scanners find it but the zip file was unencrypted with no password protection and after extracting it I had access to the source code of the main login page. I found images which were used in the website along with two files that caught my interest, the first file was “index.html” which any web developer would have recognized to be the main file which contains all the website code and the second file was “index.php”. This is responsible for running any code mentioned in it before redirecting them to the website and also contains information on how to load the main website. In this case the file “index.php” collected the IP address of any victim that visited the website and then redirected them to the login page.
Contents of “file-2.zip” ^
Contents of “index.php” ^
Diving a bit into the “index.html” file I was looking around for how the credentials are collected and stored or sent to a remote server. After reading through the code I found that the code had a very basic logic for collecting the victim's data. So basically when the victim entered their credentials on the website and clicked on the login button, their data was sent to a different server and the user was redirected to a cloudflare maintenance page which just said this page is under maintenance which gave the user the idea that maybe the page is not working or the login was not successful but in the back end the victims credentials are already sent to the owner of the website.
Part of “index.html” that collects the victims data and sends it to their server ^
What did we learn? :
All the above information shows how complicated the methods to phish people have gotten with attackers placing in active challenges within the code or how the websites are served to the victim. This is a major improvement on their part which also makes it difficult for the everyday user who may not be tech savvy enough to spot these immediately or even experienced individuals may sometimes overlook the small signs and fall in these traps and by the time they realize, it will be too late.
Now there are some steps that you can take if you fall victim to such websites that might save your account if done in time:
Change your passwords immediately by going to the official website and enable 2 factor authentication.
Go to your accounts settings and all major social media platforms have an option known as “active sessions” or “logged in accounts” and sign out all the devices this may include your current device but doing this step ensures that you accidentally don't leave an unknown device signed in. After signing in, use your new password and 2 factor authentication to sign in again.
If you have used the same password on any other websites or social media accounts change asap as attacks often try passwords phished from one platform on other related platforms to see if they can gain access to more of your accounts.
Check to see if your account recovery information has been changed, attackers like to do this to completely deny access of the account to the victim.
Keep an eye on your inbox for mails informing you about login attempts on your accounts, you can confirm if these are your devices as most mail providers show the device that logged in along with the login date, time and location.
Run an antivirus scan using the built in OS scanner or by using a third party solution.
Once you have made sure your accounts and device have been secured, report the page to the social media site it was impersonating, for example in this situation this can be reported to instagram so that these pages can be taken down.
Next time you encounter a page asking for your login, don’t enter your credentials right away, only log in once you’ve verified that the page is legitimate. Staying cautious is the simplest way to avoid falling into traps like this.